数据密集型应用设计
December 10, 2021
第一章 可靠性、可扩展性、可维护性 #
数据密集型应用和计算密集型应用
现今很多应用程序都是 数据密集型(data-intensive) 的,而非 计算密集型(compute-intensive) 的。因此CPU很少成为这类应用的瓶颈,更大的问题通常来自数据量、数据复杂性、以及数据的变更速度。
数据密集型应用通常由标准组件构建而成,标准组件提供了很多通用的功能;例如,许多应用程序都需要:
存储数据,以便自己或其他应用程序之后能再次找到 (数据库(database))
记住开销昂贵操作的结果,加快读取速度(缓存(cache))
允许用户按关键字搜索数据,或以各种方式对数据进行过滤(搜索索引(search indexes))
向其他进程发送消息,进行异步处理(流处理(stream processing))
定期处理累积的大批量数据(批处理(batch processing))
对应可选的组件在我映像中可以有:
数据库:mysql, postgresql
缓存: redis, memcached
搜索索引: elastic search, sonic, redis search
流处理: kafka, redis stream
批处理: linux cron, golang timer
使用较小的通用组件创建了一个全新的、专用的数据系统。
如何衡量一个系统的好坏 #
设计数据系统或服务时可能会遇到很多棘手的问题,例如:当系统出问题时,如何确保数据的正确性和完整性?当部分系统退化降级时,如何为客户提供始终如一的良好性能?当负载增加时,如何扩容应对?什么样的 API 才是好的 API?
可靠性(Reliability)
系统在困境(adversity)(硬件故障、软件故障、人为错误)中仍可正常工作(正确完成功能,并能达到期望的性能水准)。
故障通常定义为系统的一部分状态偏离其标准,而失效则是系统作为一个整体停止向用户提供服务。故障的概率不可能降到零,因此最好设计容错机制以防因故障而导致失效。
硬件错误的解决:为了减少系统的故障率,第一反应通常都是增加单个硬件的冗余度,例如:磁盘可以组建 RAID,服务器可能有双路电源和热插拔 CPU,数据中心可能有电池和柴油发电机作为后备电源,某个组件挂掉时冗余组件可以立刻接管。
软件错误的解决:仔细考虑系统中的假设和交互;彻底的测试;进程隔离;允许进程崩溃并重启;测量、监控并分析生产环境中的系统行为。
人为错误的解决:
可扩展性(Scalability)
有合理的办法应对系统的增长(数据量、流量、复杂性)
可维护性(Maintainability)
许多不同的人(工程师、运维)在不同的生命周期,都能高效地在系统上工作(使系统保持现有行为,并适应新的应用场景)。
从人的角度看:可靠就是能共困苦,同富贵;可扩展就是学习能力强,心胸广阔;可维护就是对人对己无偏见、无特例。
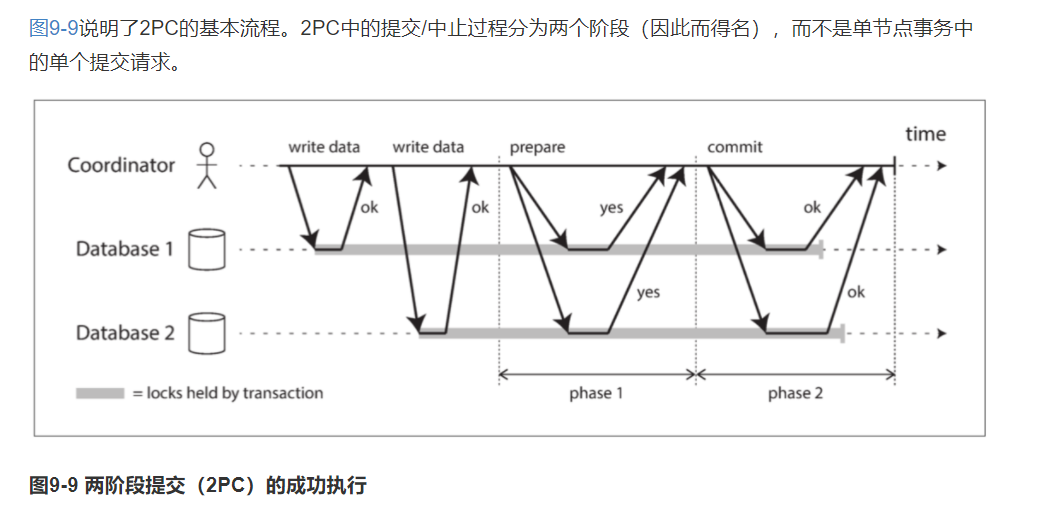
2PC(两阶段提交) #
2PC,two-phase commit,两阶段提交。
一种用于实现跨多个节点的原子事务提交的算法,即确保所有节点提交或所有节点中止。