July 17, 2021
linux epoll
#
wiki
手册
why
#
what
#
Linux内核的可扩展I/O事件通知机制。
于Linux 2.5.44首度登场,它设计目的旨在取代既有POSIX select(2)与poll(2)系统函数,让需要大量操作文件描述符的程序得以发挥更优异的性能(举例来说:旧有的系统函数所花费的时间复杂度为O(n),epoll的时间复杂度O(log n))。epoll 实现的功能与 poll 类似,都是监听多个文件描述符上的事件。
how
#
epoll 通过使用红黑树(RB-tree)搜索被监控的文件描述符(file descriptor)。
在 epoll 实例上注册事件时,epoll 会将该事件添加到 epoll 实例的红黑树上并注册一个回调函数,当事件发生时会将事件添加到就绪链表中。
int epoll_create(int size);
在内核中创建epoll实例并返回一个epoll文件描述符。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
向 epfd 对应的内核epoll 实例添加、修改或删除对 fd 上事件 event 的监听。op 可以为 EPOLL_CTL_ADD, EPOLL_CTL_MOD, EPOLL_CTL_DEL 分别对应的是添加新的事件,修改文件描述符上监听的事件类型,从实例上删除一个事件。如果 event 的 events 属性设置了 EPOLLET flag,那么监听该事件的方式是边缘触发。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
当 timeout 为 0 时,epoll_wait 永远会立即返回。而 timeout 为 -1 时,epoll_wait 会一直阻塞直到任一已注册的事件变为就绪。当 timeout 为一正整数时,epoll 会阻塞直到计时 timeout 毫秒终了或已注册的事件变为就绪。因为内核调度延迟,阻塞的时间可能会略微超过 timeout 毫秒。
...January 17, 2021
AOP
#
面向切面编程(AOP: Aspect Oriented Program)。
划分,重复,复用
#
我们知道,面向对象的特点是继承、多态和封装。而封装就要求将功能分散到不同的对象中去,这在软件设计中往往称为职责分配。实际上也就是说,让不同的类设计不同的方法。这样代码就分散到一个个的类中去了。这样做的好处是降低了代码的复杂程度,使类可重用。
出现的问题:
但是人们也发现,在分散代码的同时,也增加了代码的重复性。什么意思呢?比如说,我们在两个类中,可能都需要在每个方法中做日志。按面向对象的设计方法,我们就必须在两个类的方法中都加入日志的内容。也许他们是完全相同的,但就是因为面向对象的设计让类与类之间无法联系,而不能将这些重复的代码统一起来。
想法1:
也许有人会说,那好办啊,我们可以将这段代码写在一个独立的类独立的方法里,然后再在这两个类中调用。但是,这样一来,这两个类跟我们上面提到的独立的类就有耦合了,它的改变会影响这两个类。
那么,有没有什么办法,能让我们在需要的时候,随意地加入代码呢?
这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程。
一般而言,我们管切入到指定类指定方法的代码片段称为切面,而切入到哪些类、哪些方法则叫切入点。
有了AOP,我们就可以把几个类共有的代码,抽取到一个切片中,等到需要时再切入对象中去,从而改变其原有的行为。
OOP从横向上区分出一个个的类来,而AOP则从纵向上向对象中加入特定的代码。
从技术上来说,AOP基本上是通过代理机制实现的。
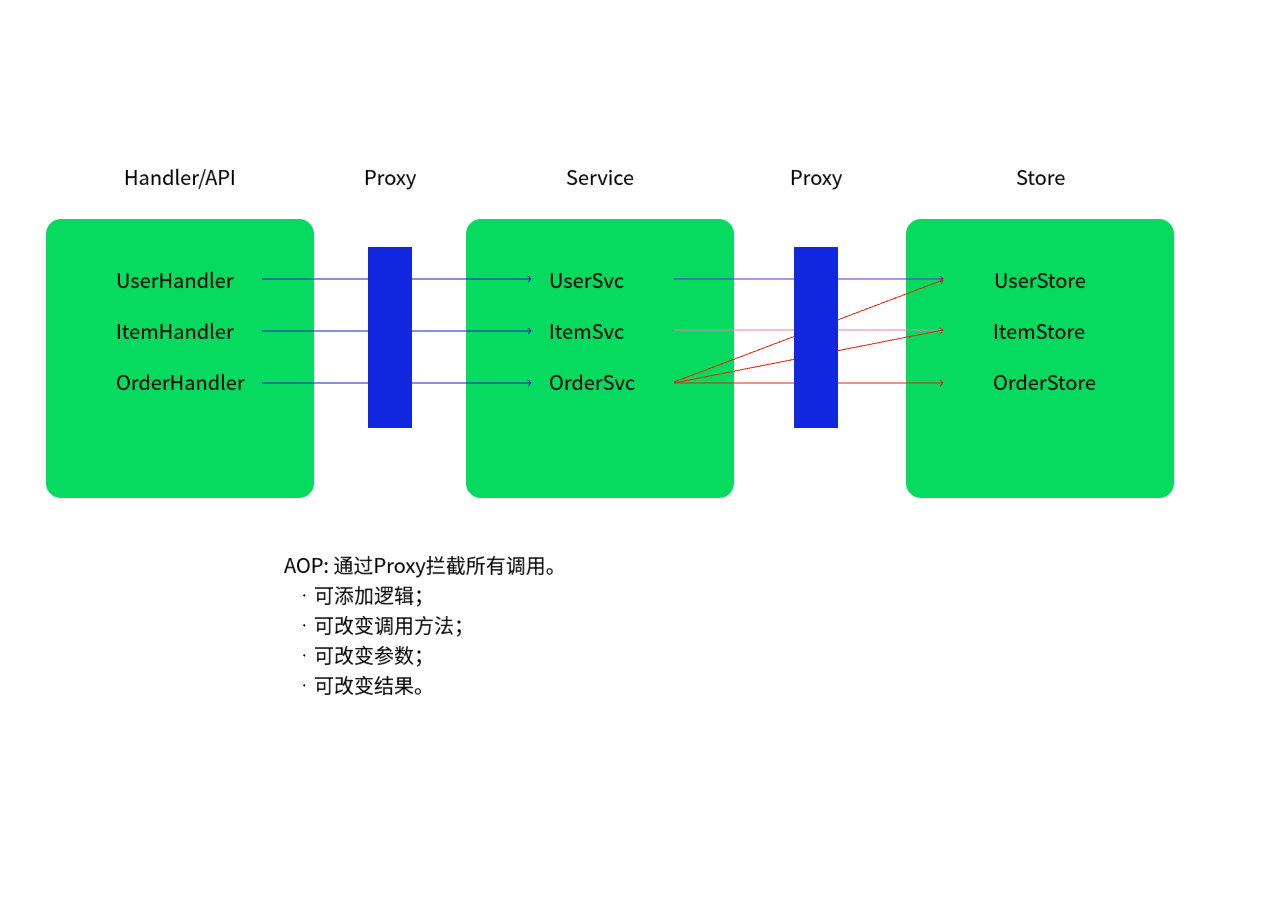
Go实现AOP – 层间代理
#
假设有store,从数据库获取数据,其中有方法IUserStore.GetByID,传入id参数,返回用户信息:
type IUserStore interface {
GetByID(ctx context.Context, id int) (User, error)
}
另外有service,刚好有用户id并且需要拿到用户信息,于是依赖了上述IUserStore:
type IUserSrv interface {
CheckUser(ctx context.Context, id int) error // 获取用户信息,然后检查用户某些属性
}
type userImpl struct {
userStore IUserStore
}
func (impl userImpl) CheckUser(ctx context.Context, id int) error {
user, err := impl.userStore.GetByID(ctx, id)
if err != nil {
return err
}
// 使用user数据做一些操作
_ = user
}
上面所描述的是一个最简单的情况,如果我们要在userImpl.CheckUser里对impl.userStore.GetByID方法调用添加耗时统计,依然十分简单。
func (impl userImpl) CheckUser(ctx context.Context, id int) error {
begin := time.Now()
user, err := impl.userStore.GetByID(ctx, id)
if err != nil {
return err
}
fmt.Println(time.Since(begin)) // 统计耗时
// 使用user数据做一些操作
_ = user
}
但是,如果方法里调用的类似impl.userStore.GetByID的方法非常之多,逻辑非常之复杂时,这样一个一个的添加,必然非常麻烦、非常累。
...December 18, 2020
ctx
#
1.why
goroutine号称百万之众,互相之间盘根错节,难以管理控制。为此,必须提供一种机制来管理控制它们。
各自为战
#
package main
import (
"fmt"
"time"
)
func main() {
// start first
go func() {
fmt.Println(1)
}()
// start second
go func() {
fmt.Println(2)
}()
time.Sleep(time.Second)
}
万法归一
#
package main
import (
"fmt"
"sync"
)
func main() {
wg := new(sync.WaitGroup)
// start first
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println(1)
}()
// start second
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println(2)
}()
wg.Wait()
}
可以看到使用waitgroup可以控制多个goroutine必须互相等待,直到最后一个完成才会全部完成。
...软弱如绵羊,却生造出老虎护幼崽的形象,只需一句“都是为了他”。
dot: 在模板里表示为.,表示当前作用域。
{{range}}, {{if}}, {{with}}均有自己的作用域。
{{if pipeline}}和{{with pipeline}}的区别是,前者不会修改.的值,而后者会。
with
#
with设置.的值:
{{with pipeline}} T1 {{end}}
{{with pipeline}} T1 {{else}} T0 {{end}}
当pipeline不为0值时,点.设置为pipeline运算的值,否则跳过。
例如:
{{with "hello"}} {{println .}} {{end}}
将输入hello,因为.被设置为了hello.