January 26, 2022
智能合约
#
智能合约wiki
(英语:Smart contract)是一种特殊协议,在区块链内制定合约时使用,当中内含了代码函数 (Function),亦能与其他合约进行交互、做决策、存储资料及发送以太币等功能。智能合约主要提供验证及执行合约内所订立的条件。智能合约允许在没有第三方的情况下进行可信交易。这些交易可追踪且不可逆转。
安全问题
#
智能合约是“执行合约条款的计算机交易协议”。区块链上的所有用户都可以看到基于区块链的智能合约。但是,这会导致包括安全漏洞在内的所有漏洞都可见,并且可能无法迅速修复。
这样的攻击难以迅速解决,例如:
2016年6月The DAOEther的漏洞造成损失5000万美元,而开发者试图达成共识的解决方案。DAO的程序在黑客删除资金之前有一段时间的延迟。以太坊软件的一个硬分叉在时限到期之前完成了攻击者的资金回收工作。
以太坊智能合约中的问题包括合约编程Solidity、编译器错误、以太坊虚拟机错误、对区块链网络的攻击、程序错误的不变性以及其他尚无文档记录的攻击。
2018年4月22日, BeautyChain智能合约出现重大漏洞,黑客通过此漏洞无限生成代币,导致 BitEclipse (BEC)的价值接近归零。同月25日,SmartMesh出现疑似重大安全漏洞,宣布暂停所有SMT交易和转账直至另行通知,导致损失约1.4亿美金。28日,EOS被指可能存在BEC代币合约类似的整数溢出漏洞,但没消息详细说明。5月24日, BAI交易存在大量异常问题, 损失金额未知。8月22日, GODGAME 合约被黑客入侵,GOD智能合约上的以太坊总数归零。
合约开发、测试和部署
#
eth智能合约文档
vending machine(自动售货机): money + snack selection = snack dispensed, 给钱并选择小吃,小吃就会出来 – 是给刚好的钱,还是过量的钱,过量了在发放小吃的同时退钱呢?
合约长这样:
// 表明使用的sol版本
pragma solidity 0.8.7;
// Solidity 合约类似于面向对象语言中的类。合约中有用于数据持久化的状态变量,和可以修改状态变量的函数。 调用另一个合约实例的函数时,会执行一个 EVM 函数调用,这个操作会切换执行时的上下文,这样,前一个合约的状态变量就不能访问了。
contract VendingMachine {
// Declare state variables of the contract
address public owner; // owner变量
mapping (address => uint) public cupcakeBalances; // cupcakeBalances变量
// 创建合约时,合约的构造函数会执行一次。构造函数是可选的。只允许有一个构造函数,这意味着不支持重载。
// When 'VendingMachine' contract is deployed:
// 1. set the deploying address as the owner of the contract
// 2. set the deployed smart contract's cupcake balance to 100
constructor() {
owner = msg.sender; // 设置部署本合约的地址为合约所有者
// address(this)是将this转型为地址吗?
// this不是代表合约对象吗,还能转为address?
cupcakeBalances[address(this)] = 100; // 设置蛋糕余量
}
// Allow the owner to increase the smart contract's cupcake balance
function refill(uint amount) public { // public表示方法可导出
require(msg.sender == owner, "Only the owner can refill."); // 如果前面的条件不成立,则报错,后面为内容;此处要求消息的发送者必须是本合约所有者
cupcakeBalances[address(this)] += amount; // 补充蛋糕
}
// Allow anyone to purchase cupcakes
function purchase(uint amount) public payable { // payable表示方法含有支付逻辑
require(msg.value >= amount * 1 ether, "You must pay at least 1 ETH per cupcake"); // 此处要求每个蛋糕最少支付一个eth
require(cupcakeBalances[address(this)] >= amount, "Not enough cupcakes in stock to complete this purchase"); // 此处要求蛋糕余量不小于需要的数量
cupcakeBalances[address(this)] -= amount; // 本合约所有者减少蛋糕
cupcakeBalances[msg.sender] += amount; // 消息发送者添加蛋糕
}
}
address(this)
...January 25, 2022
源码
#
// 所有代码都需要放到包里
package color
// 导入其它包
import (
"context"
"fmt"
"strconv"
"sync"
"time"
)
// 枚举
type Color int
// 常量
const (
Red Color = 1 // 红
Blue Color = 2 // 蓝
Green Color = 3 // 绿
)
// 函数
func NewCar(
name string,
rate int,
) *Car {
return &Car{
name: name,
rate: rate,
}
}
// 类型
type Car struct {
// 类型字段
name string // 首字母小写,非导出,只能包内使用
rate int
}
// 类型方法
func (car *Car) String() string { // 首字母大写,导出,可供其它包使用
return "[Car] name: " + car.name + ", rate: " + strconv.Itoa(car.rate) + "."
}
func (car *Car) Run(
ctx context.Context, // 使用ctx实现超时控制
) {
// 定时器,每隔rate秒执行一次
ticker := time.NewTicker(time.Duration(car.rate) * time.Second)
defer ticker.Stop() // defer语句,在方法退出前执行,做收尾工作
// for range ticker.C { // 循环,遍历chan
// fmt.Printf("%s\n", car)
// }
for {
select {
case <-ticker.C:
{ // 代码块,让逻辑更聚合,更清晰
timesMutex.Lock()
count := 1
if v, ok := times[car.name]; ok {
count = v + 1
}
times[car.name] = count
timesMutex.Unlock()
}
fmt.Printf("%s\n", car)
case <-ctx.Done():
return
}
}
}
// 接口
type Runner interface {
Run(ctx context.Context)
}
// 变量
var (
// 确保*Car实现了Runner接口
_ Runner = (*Car)(nil)
timesMutex = new(sync.RWMutex) // 读写锁,唯一写,多个读,读时无写
times = make(map[string]int, 2) // 记录Car Run的次数;在声明时初始化,并配置容量
)
测试
#
package color
import (
"context"
"fmt"
"sync"
"testing"
"time"
)
func TestCar(t *testing.T) {
// 超时控制
ctx, cancel := context.WithTimeout(context.Background(), time.Second*10)
defer cancel()
// 并发执行
wg := new(sync.WaitGroup)
for _, car := range []Runner{ // 遍历切片
NewCar("lanbo", 2),
NewCar("boshi", 3),
} {
wg.Add(1) // 记录一个
go func(car Runner) {
defer wg.Done() // 完成一个
t.Run(car.(*Car).name, func(t *testing.T) { // 对接口断言,获得具体类型
car.Run(ctx)
})
}(car)
}
// 等上面均完成
wg.Wait()
timesMutex.RLock()
fmt.Printf("times: %+v\n", times)
timesMutex.RUnlock()
}
执行
#
编译:go build
...January 17, 2022
在中文里,共表示共同(至少两个人?一个人行不行?),识表示认识,组合一起成为共识,共同的认识,引申出共同的想法、共同的行为。
在英语里,con是一个词根–表示"共同",sensus表示感觉,加在一起组成consensus。
人类社会的发展催生了交易,交易的前提是双方达成共识,比如油换盐,比如钱换粮。如果你不承认我的油,不愿意与我交易,那就没办法了。
人与人之间的共识是非常难以达成的,不像歌里唱的:我说一,你说一。很多时候,我说一,他也承诺他会说一,但他没说–可能因为一些事忘了说,可能因为他突然不想说了,也有可能他被胁迫了不能说。反正就是不一而足的情况导致了意见/行为不一。
在日常生活中,特别是集市上,往往都是一手交钱、一手交货,交易完成就完成了,如果后面出现了问题–比如货不对版、钱有真伪,那就是另外的问题了。
那如果我们分别在不同的地方,没法面对面交易呢;又或者交易的东西不方便马上拿到面前来交易呢;又或者交易之后发现货不对版不想要了呢?
这时候,为了解决这些问题,某种机构应运而生。结合现在网购流行的社会,大家不难发现有哪些这类的机构。
目前的社会除了网购流行之外,是不是机器也很流行呢。那机器又是什么呢?机器能做什么,从而在这个社会如此流行呢?机器又能不能充当某类机构来完成某些事呢?
共识要素
#
某件事,事的主体,事的具体。比如购物,买卖双方、以钱易物。
机器共识
#
拜占庭将军问题
#
wiki
拜占庭将军问题(Byzantine Generals Problem),是由莱斯利·兰波特在其同名论文中提出的分布式对等网络通信容错问题。
在分布式计算中,不同的计算机通过通讯交换信息达成共识而按照同一套协作策略行动。但有时候,系统中的成员计算机可能出错而发送错误的信息,用于传递信息的通讯网络也可能导致信息损坏,使得网络中不同的成员关于全体协作的策略得出不同结论,从而破坏系统一致性。拜占庭将军问题被认为是容错性问题中最难的问题类型之一。
关键词:分布式对等、通信容错、不同计算机通过通讯交换信息从而达成共识、共识达成失败会导致系统一致性被破坏。
问题描述:
一组拜占庭将军分别各率领一支军队共同围困一座城市。
为了简化问题,将各支军队的行动策略限定为进攻或撤离两种。
因为部分军队进攻部分军队撤离可能会造成灾难性后果,因此各位将军必须通过投票来达成一致策略,即所有军队一起进攻或所有军队一起撤离。
因为各位将军分处城市不同方向,他们只能通过信使互相联系。
在投票过程中每位将军都将自己投票给进攻还是撤退的信息通过信使分别通知其他所有将军,这样一来每位将军根据自己的投票和其他所有将军送来的信息就可以知道共同的投票结果而决定行动策略。
面临问题:
系统的问题在于,可能将军中出现叛徒,他们不仅可能向较为糟糕的策略投票,还可能选择性地发送投票信息。– 出现叛徒,半真半假,选择性投票,(一人投两票) – 控制投票时间,只要不在其他人都投完之后再投,他就没法知道别人投的什么票;一人投一票,投票之后不能再投;
假设有9位将军投票,其中1名叛徒。8名忠诚的将军中出现了4人投进攻,4人投撤离的情况。这时候叛徒可能故意给4名投进攻的将领送信表示投票进攻,而给4名投撤离的将领送信表示投撤离。这样一来在4名投进攻的将领看来,投票结果是5人投进攻,从而发起进攻;而在4名投撤离的将军看来则是5人投撤离。这样各支军队的一致协同就遭到了破坏。
由于将军之间需要通过信使通讯,叛变将军可能通过伪造信件来以其他将军的身份发送假投票。而即使在保证所有将军忠诚的情况下,也不能排除信使被敌人截杀,甚至被敌人间谍替换等情况。因此很难通过保证人员可靠性及通讯可靠性来解决问题。
人可能是假的,信可能是假,空气都可能是假的;
假使那些忠诚(或是没有出错)的将军仍然能通过多数决定来决定他们的战略,便称达到了拜占庭容错。在此,票都会有一个默认值,若消息(票)没有被收到,则使用此默认值来投票。
应用:
在点对点式数字货币系统比特币里,比特币网络的运作是平行的(parallel)。各节点与终端都运算著区块链来达成工作量证明(PoW)。工作量证明的链接是解决比特币系统中拜占庭问题的关键,避免有问题的节点(即前文提到的“反叛的将军”)破坏数字货币系统里交易帐的正确性,是对整个系统的运行状态有着重要的意义。
在一些飞行器(如波音777)的系统中也有使用拜占庭容错。而且由于是即时系统,容错的功能也要能尽快回复,比如即使系统中有错误发生,容错系统也只能做出一微秒以内的延迟。
一些航天飞机的飞行系统甚至将容错功能放到整个系统的设计之中。
拜占庭容错机制是将收到的消息(或是收到的消息的签名)转交到其他的接收者。这类机制都假设它们转交的消息都可能念有拜占庭问题。在高度安全要求的系统中,这些假设甚至要求证明错误能在一个合理的等级下被排除。当然,要证明这点,首先遇到的问题就是如何有效的找出所有可能的、应能被容错的错误。这时候会试着在系统中加入错误插入器。
eth共识
#
Beacon
#
Beacon:信标
eth2将要升级的共识机制,即将使用的基于eth1和PoS算法的共识。
信标链不支持叔块了。
信标链和经典链在校验header时的不同:
(a) The following fields are expected to be constants:
- difficulty is expected to be 0 – 难度固定为0
- nonce is expected to be 0 – 随机数固定为0
- unclehash is expected to be Hash(emptyHeader)
to be the desired constants – 叔块哈希固定为空值
(b) the timestamp is not verified anymore
(c) the extradata is limited to 32 bytes
...
January 11, 2022
树,保持高效在于平衡,高度低。
红黑树如何做到的呢?
定义
#
wiki
#
红黑树(英语:Red–black tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型用途是实现关联数组。它在1972年由鲁道夫·贝尔发明,被称为"对称二叉B树",它现代的名字源于Leo J. Guibas和罗伯特·塞奇威克于1978年写的一篇论文。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在O(log n)时间内完成查找、插入和删除,这里的n是树中元素的数目。
性质
#
红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
节点是红色或黑色。
根是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
从**任一节点到其每个叶子**的所有简单路径都包含**相同数目的黑色节点**。
一句话概况:或红或黑,首尾皆黑,红子必黑,任一点至所有尾含黑同数。
为确保任一点至所有尾含黑同数,路径中必须插入红点,而在哪个位置插呢(必须考虑红子必黑原则)?
这些约束确保了红黑树的关键特性:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
要知道为什么这些性质确保了这个结果,注意到性质4导致了路径不能有两个毗连的红色节点就足够了。最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点。因为根据性质5所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
在很多树数据结构的表示中,一个节点有可能只有一个子节点,而叶子节点包含数据。用这种范例表示红黑树是可能的,但是这会改变一些性质并使算法复杂。为此,本文中我们使用"nil叶子"或"空(null)叶子",如上图所示,它不包含数据而只充当树在此结束的指示。这些节点在绘图中经常被省略,导致了这些树好像同上述原则相矛盾,而实际上不是这样。与此有关的结论是所有节点都有两个子节点,尽管其中的一个或两个可能是空叶子。
实现
#
操作
#
因为每一个红黑树也是一个特化的二叉查找树,因此红黑树上的只读操作与普通二叉查找树上的只读操作相同。然而,在红黑树上进行插入操作和删除操作会导致不再符合红黑树的性质。恢复红黑树的性质需要少量(O(log n))的颜色变更(实际是非常快速的)和不超过三次树旋转(对于插入操作是两次)。虽然插入和删除很复杂,但操作时间仍可以保持为O(log n)次。
- 我们首先以二叉查找树的方法增加节点并标记它为红色。(如果设为黑色,就会导致根到叶子的路径上有一条路上,多一个额外的黑节点,这个是很难调整的。但是设为红色节点后,可能会导致出现两个连续红色节点的冲突,那么可以通过**颜色调换(color flips)和
树旋转**来调整。)
树旋转
#
对二叉树的一种操作,不影响元素的顺序,但会改变树的结构,将一个节点上移、一个节点下移。树旋转会改变树的形状,因此常被用来将较小的子树下移、较大的子树上移,从而降低树的高度、提升许多树操作的效率。
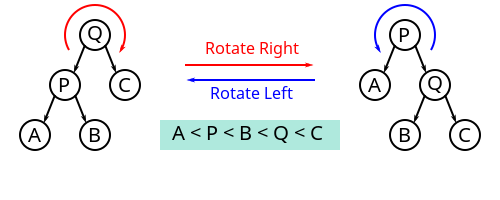
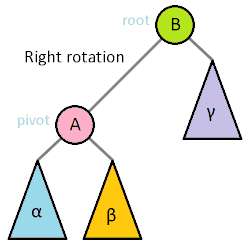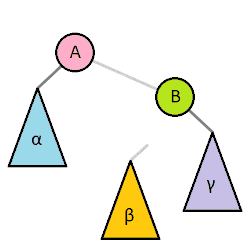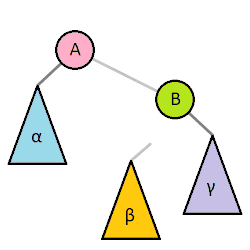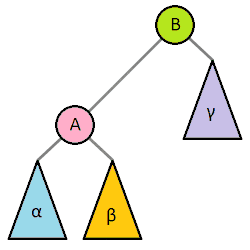
对一棵树进行旋转时,这棵树的根节点是被旋转的两棵子树的父节点,称为旋转时的根(英语:root);如果节点在旋转后会成为新的父节点,则该节点为旋转时的转轴(英语:pivot)。
上图中,树的右旋操作以 Q 为根、P 为转轴,会将树顺时针旋转。相应的逆操作为左旋,会以 Q 为转轴,将树逆时针旋转。
理解树旋转过程的关键,在于理解其中不变的约束。旋转操作不会导致叶节点顺序的改变(可以理解为旋转操作前后,树的中序遍历结果是一致的),旋转过程中也始终受二叉搜索树的主要性质约束:右子节点比父节点大、左子节点比父节点小。尤其需要注意的是,进行右旋转时,旋转前根的左节点的右节点(例如上图中以 Q 为根的 B 节点)会变成根的左节点,根本身则在旋转后会变成新的根的右节点,而在这一过程中,整棵树一直遵守着前面提到的几个约束。相反的左旋转操作亦然。
如果将根记为 Root、转轴记为 Pivot、子节点中与旋转方向相同的一侧记为 RS(旋转侧,英语:Rotation Side)、旋转对侧记为 OS(英语:Opposite Side),则上图中 Q 节点的 RS 为 C、OS 为 P,将其右旋转的伪代码为:
...January 10, 2022
crossbeam
#
crossbeam: Tools for concurrent programming in Rust.
channel example
#
use crossbeam_channel::unbounded;
let (s, r) = unbounded();
s.send("Hello, world!").unwrap();
assert_eq!(r.recv(), Ok("Hello, world!"));
unbounded(无限) channel发送时不用等接收端就绪。
另外还有bounded channel可在新建时指定容量,后续发送的消息数不能超过该数据 – 除非中间有消息被取走了
当bounded channel容量设为0时,发送前必须等接收端就绪,一般可用于线程间等待。
更多介绍
与标准库的sync::mpsc对比
epoch
#
Pin 做了什么?
crossbeam在实现无锁并发结构时,采用了基于代的内存回收方式1,这种算法的内存管理开销和数据对象的数量无关,只和线程的数量相关,因此在 以上模型中可以表现出更好的一致性和可预测性。不过Rust中的所有权系统已经保证了内存安全,那为什么还需要做额外的内存回收呢?这个问题的关键点 就在要实现无锁并发结构。如果使用标准库中的Arc自然就不会有内存回收的问题,但对Arc进行读写是需要锁的。
crossbeam-channel文章
digest
#
This crate provides traits which describe functionality of cryptographic hash functions and Message Authentication algorithms.
...January 10, 2022
缓存读
#
从缓存读,如果读到了,直接返回;如果读不到,继续去数据库读(singleflight),读到后,更新缓存,返回结果。
缓存写
#
为什么是删缓存,而不是更新缓存呢?
主要是怕两个并发的写操作导致脏数据。
删除缓存和更新磁盘谁先谁后呢?
1.如果先删除缓存,再更新磁盘时的问题:
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。 – 删了缓存,未完成数据库修改
另一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。 – 因为上面的请求里修改数据库的部分还未完成
随后数据变更的程序完成了数据库的修改。– 这时才完成,可缓存已经填充了之前的旧值了
来到这,数据库和缓存中的数据就不一样了。
2.先更新磁盘,再删除缓存的问题:
先更新数据库,再删除缓存,如果数据库更新了,但是缓存删除失败了,那么缓存中的数据还是旧数据,出现数据不一致
先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。
比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
参照
代码
#
package cache
// 缓存,一般先将数据从磁盘读出来写到内存里,供用户高速访问,减少读磁盘 -- 快取
// 另有缓冲,将数据先写到内存里,待装满后一次性写入磁盘,可以少写很多次 -- 缓冲
//
// 不难看出,无论快取还是缓冲,都涉及到内存和磁盘的读写。
//
// 首先,对于缓存,目前使用较多的中间件是redis、memcached等,当然也有自己在程序中内置map充当缓存的。
// 那么,下面来看下如何在内存和磁盘之间同步数据:
type Cache interface {
// exp表示当前时间后的exp秒后过期,传0则无过期
Set(key, value string, exp int) error
Del(key string) error
Get(key string) (value string, err error)
}
type Store interface {
Create(key, value string, exp int) error
Delete(key string) error
Update(key, value string, exp int) error
Get(key string) (vlaue string, err error)
}
// 用户 有增删改查四个操作,在操作时,对应的缓存和磁盘如何变化呢?
type Client struct {
cache Cache
store Store
}
func NewClient(
cache Cache,
store Store,
) *Client {
return &Client{
cache: cache,
store: store,
}
}
const (
defExp = 300
)
// Add 先写磁盘还是缓存呢?
func (client *Client) Add(key, value string) {
// 会不会已经在Store里存在了呢?
// 先从Store Get一次?
// 一般来说,key都是唯一的:
// 此时,必须请求一次Store,确认数据不存在;如果此时数据存在,直接返回错误
if v, err := client.store.Get(key); err == nil && v != "" {
return
}
// 缓存里会不会也有呢?
// 先从Cache里读一次?
// 如果能通过业务检查,正常来说,缓存里是没有的;
// 写磁盘
client.store.Create(key, value, defExp)
// 1. 写缓存
// client.cache.Set(key, value, defExp)
// 2. 不写,等获取时从磁盘取
}
func (client *Client) Mod(key, value string) {
// 更新磁盘
client.store.Update(key, value, defExp)
// 1. 更新缓存
// client.cache.Set(key, value, defExp)
// 2. 不更新,删掉缓存,等获取时从磁盘取 -- Cache Aside Pattern(旁路缓存方案): 一个 lazy 计算的思想,不要每次都重新做复杂的计算,而是让它到需要被使用的时候再重新计算
client.cache.Del(key)
}
func (client *Client) Del(key string) {
// 从磁盘删除
client.store.Delete(key)
// 1. 从缓存删除
client.cache.Del(key)
}
func (client *Client) Get(key string) (string, error) {
// 从Cache获取
v, err := client.cache.Get(key)
if err != nil {
return "", err
}
if v == "" {
// 以SingleFlight方式从Store读:
// https://pkg.go.dev/golang.org/x/sync/singleflight
// 这个库的主要作用就是将一组相同的请求合并成一个请求,实际上只会去请求一次,然后对所有的请求返回相同的结果。
// 在一个请求的时间周期内实际上只会向底层的数据库发起一次请求大大减少对数据库的压力。
{
valueFromStore, err := client.store.Get(key)
if err != nil {
return "", err
}
v = valueFromStore
}
// 设置Cache
client.cache.Set(key, v, defExp)
}
return v, nil
}
December 24, 2021
ebpf: 扩展伯克利包过滤器。
下面的内容主要来源于
译文。
用处
#
目前,主要有两大组触发器。
第一组用于处理网络数据包和管理网络流量。它们是 XDP、流量控制事件及其他几个事件。
以下情况需要用到这些事件:
创建简单但非常有效的防火墙。Cloudflare 和 Facebook 等公司使用 BPF 程序来过滤掉大量的寄生流量,并打击最大规模的 DDoS 攻击。由于处理发生在数据包生命的最早阶段,直接在内核中进行(BPF 程序的处理有时甚至可以直接推送到网卡中进行),因此可以通过这种方式处理巨量的流量。这些事情过去都是在专门的网络硬件上完成的。
创建更智能、更有针对性、但性能更好的防火墙——这些防火墙可以检查通过的流量是否符合公司的规则、是否存在漏洞模式等。例如,Facebook 在内部进行这种审计,而一些项目则对外销售这类产品。
创建智能负载均衡器。最突出的例子就是 Cilium 项目,它最常被用作 K8s 集群中的网格网络。Cilium 对流量进行管理、均衡、重定向和分析。所有这些都是在内核运行的小型 BPF 程序的帮助下完成的,以响应这个或那个与网络数据包或套接字相关的事件。
这是第一组与网络问题相关并能够影响网络通信行为的触发器。第二组则与更普遍的可观察性相关;在大多数情况下,这组的程序无法影响任何事件,而只能“观察”。这才是我更感兴趣的。
这组的触发器有如下几个:
perf 事件(perf events)——与性能和 perf Linux 分析器相关的事件:硬件处理器计数器、中断处理、小 / 大内存异常拦截等等。例如,我们可以设置一个处理程序,每当内核需要从 swap 读取内存页时,该处理程序就会运行。例如,想象有这样一个实用程序,它显示了当前所有使用 swap 的程序。
跟踪点(tracepoints)——内核源代码中的静态(由开发人员定义)位置,通过附加到这些位置,你可以从中提取静态信息(开发人员先前准备的信息)。在这种情况下,静态似乎是一件坏事,因为我说过,日志的缺点之一就是它们只包含了程序员最初放在那里的内容。从某种意义上说,这是正确的,但跟踪点有三个重要的优势:
有相当多的跟踪点散落在内核中最有趣的地方
当它们不“开启”时,它们不使用任何资源
它们是 API 的一部分,它们是稳定的,不会改变。这非常重要,因为我们将提到的其他触发器缺少稳定的 API。
例如,假设有一个关于显示的实用程序,内核出于某种原因没有给它时间执行。你坐着纳闷为什么它这么慢,而 pprof 却没有显示任何什么有趣的东西。
USDT——与跟踪点相同,但是它适用于用户空间的程序。也就是说,作为程序员,你可以将这些位置添加到你的程序中。并且许多大型且知名的程序和编程语言都已经采用了这些跟踪方法:例如 MySQL、或者 PHP 和 Python 语言。通常,它们的默认设置为“关闭”,如果要打开它们,需要使用 enable-dtrace 参数或类似的参数来重新构建解释器。是的,我们还可以在 Go 中注册这种类跟踪。你可能已经识别出参数名称中的单词 DTrace。关键在于,这些类型的静态跟踪是由 Solaris) 操作系统中诞生的同名系统所推广的。例如,想象一下,何时创建新线程、何时启动 GC 或与特定语言或系统相关的其他内容,我们都能够知道是怎样的一种场景。
这是另一种魔法开始的地方:
Ftrace 触发器为我们提供了在内核的任何函数开始时运行 BPF 程序的选项。这是完全动态的。这意味着内核将在你选择的任何内核函数或者在所有内核函数开始执行之前,开始执行之前调用你的 BPF 函数。你可以连接到所有内核函数,并在输出时获取所有调用的有吸引力的可视化效果。
...
December 24, 2021
带领,今天突然用到这个“带”字时,觉得它不是我印象中的“带”字,这是为什么呢?
很重的一种陌生感迎面而来,这真的是曾经伴随我历经千测万考的字吗?
这种突然觉得某个曾经很熟悉的字很陌生的感觉,真的很奇怪。
December 20, 2021
etcd
#
raft
#
由多个节点组成的集群维护着一个可复制状态机的协议。通过复制日志来保持状态机的同步。
可理解的共识算法
状态机以消息为输入。消息可以是一个本地定时器更新,或一条网络消息。输出一个3元结构:[]Messages, []LogEntries, NextState,分别是消息列表、日志条目列表、下个状态。同样状态的状态机,在相同输入时总是输出相同结果。
插曲
#
人、联系、共识
人生下来,触摸着这个世界的人和物,做着或有趣或无聊的事,建立起或浅或深的联系。
当两个人面对面时,就某个想法达成一致或不一致,非常容易。
如果两个人不是面对面呢?
如果不只两个人,同坐在祠堂里呢?
如果不止两个人,还分散在不同地点呢?
那么,为什么要达成共识呢?
因为有些事必须达成共识才能执行,比如,两个人双向奔赴。
如果彼此异心,一个向东,一个往南,事情就办不成了。
所以,共识是大伙成事的前提。
共识,除了就某件事所要达成的结果,也要考虑所使用的方法。
有可能是步步为营,走一步算一步,也就是每走一步再就下一步达成共识。
也有可能是,一次性就接下来的几步均达成共识,然后各自执行。
message type
#
// For description of different message types, see:
// https://pkg.go.dev/go.etcd.io/etcd/raft/v3#hdr-MessageType
type MessageType int32
const (
// 选举时使用;
// 如果节点是一个follower或candidate,它在选举超时前没有收到任何心跳,它就回传递MsgHup消息给它自己的Step方法,然后成为(或保持)一个candidate从而开启一个新的选举
MsgHup MessageType = 0
// 一个内部类型,它向leader发送一个类型为“MsgHeartbeat”的心跳信号
// 如果节点是一个leader,raft里的tick函数将会是“tickHeartbeat”,触发leader周期性地发送“MsgHeartbeat”消息给它的followers
MsgBeat MessageType = 1
// 提议往它的日志条目里追加数据;
// 这是一个特别的类型,由follower反推提议给leader(正常是leader提议,follower执行);
// 发给leader的话,leader调用“appendEntry”方法追加条目到它的日志里,然后调用“bcastAppend”方法发送这些条目给它的远端节点;
// 发给candidate的话,它们直接丢弃该消息
// 发给follower的话,follower会将消息存储到它们的信箱里。会把发送者的id一起存储,然后转发给leader。
MsgProp MessageType = 2
// 包含了要复制的日志条目
// leader调用“bcastAppend”(里面调用“sendAppend”),发送“一会要被复制的日志”消息;
// 当candidate收到消息后,在它的Step方法里,它马上回退为follower,因为这条消息表明已经存在一个有效leader了。
// candidate和follower均会返回一条“MsgAppResp”类型消息以作响应。
MsgApp MessageType = 3
// 调用“handlerAppendEntries”方法
MsgAppResp MessageType = 4
// 请求集群中的节点给自己投票;
// 当节点是follower或candidate,并且它们的Step方法收到了“MsgHup”消息,节点调用“campaign”方法去提议自己成为一个leader。一旦“campaign”方法被调用,节点成为candidate,并发送“MsgVote”给集群中的远端节点请求投票。
// 当leader或candidate的Step方法收到该消息,并且消息的Term比它们的Term小,“MsgVote”将被拒绝。
// 当leader或candidate收到的消息的Term要更大时,它会回退为follower。
// 当follower收到该消息,仅当发送者的最后的term比“MsgVote”的term要大,或发送者的最后term等于“MsgVote”的term(但发送者的最后提交index大于等于follower的),
MsgVote MessageType = 5
// 投票响应;
// 当candidate收到后,它会统计选票,如果大于majority(quorum),它成为leader并调用“bcastAppend”。如果candidate收到大量的否决票,它将回退到follower
MsgVoteResp MessageType = 6
// 请求安装一个快照消息;
// 当一个节点刚成为leader,或者leader收到了“MsgProp”消息,它调用“bcastAppend”方法(里面再调用“sendAppend”)方法到每个follower。在“sendAppend”方法里,如果一个leader获取term或条目失败了,leader通过"MsgSnap"消息请求快照。
MsgSnap MessageType = 7
// leader发送心跳;
// 当candidate收到“MsgHeartbeat”,并且消息的term比candidate的大,candidate回退到follower并且更新它的提交index为这次心跳里的值。然后candidate发送消息到它的信箱。
// 当消息发送到follower的Step方法,并且消息的term比follower的大,follower更新它的leader id
MsgHeartbeat MessageType = 8
// 心跳响应;
// leader收到后就知道有哪些follower响应了。
// 只有当leader的最后提交index比follower的Match index大时,leader执行“sendAppend”方法
MsgHeartbeatResp MessageType = 9
// 表明请求没有被交付;
// 当“MsgUnreachable”被传送到leader的Step方法,leader发现follower无法到达,很有可能“MsgApp”都丢失了。当follower的进度状态为复制时,leader设置它回probe(哨兵)
MsgUnreachable MessageType = 10
// 表明快照安装消息的结果
// 当一个follower拒绝了“MsgSnap”,这显示快照请求失败了--因为网络原因;**leader认为follower成为哨兵了**?(Then leader considers follower's progress as probe.);
// 当“MsgSnap”没有被拒绝,它表明快照成功了,leader设置follower的进度为哨兵,并恢复它的日志复制
MsgSnapStatus MessageType = 11
MsgCheckQuorum MessageType = 12
MsgTransferLeader MessageType = 13
MsgTimeoutNow MessageType = 14
MsgReadIndex MessageType = 15
MsgReadIndexResp MessageType = 16
// "MsgPreVote"和“MsgPreVoteResp”用在可选的两阶段选举协议上;
// 当Config.PreVote为true,将会进行一次预选举,除非预选举表明竞争节点会赢,否则没有节点会增加它们的term值。
// 这最小化了**一个发生了分区的节点重新加入到集群时**会带来的中断/干扰
MsgPreVote MessageType = 17
MsgPreVoteResp MessageType = 18
)
raft, Node and RawNode
#
type Node interface {
// ...
}
func StartNode(...) Node {
rn, err := NewRawNode(...)
if err != nil {
panic(err)
}
n := newNode(rn)
go n.run()
return &n
}
func NewRawNode(config *Config) (*RawNode, error) {
r := newRaft(config)
rn := &RawNode{
raft: r,
}
...
return rn, nil
}
type node struct { // impl Node interface
...
rn *RawNode
}
func newNode(rn *RawNode) node {
return node{
...
}
}
实现
#
使用
#
存储
#
bbolt
...December 20, 2021
问题如图:
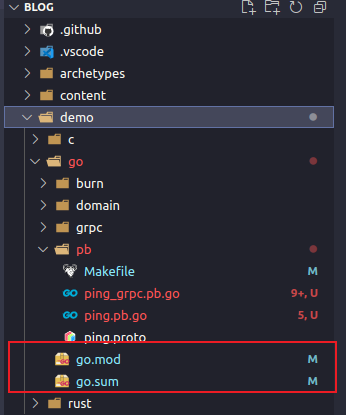
解决:
添加配置:
{
// ...
"gopls": {
"experimentalWorkspaceModule": true
},
// ...
}
等go 1.18的workspace模式推出之后,应该就不需要配置这个了。
参考